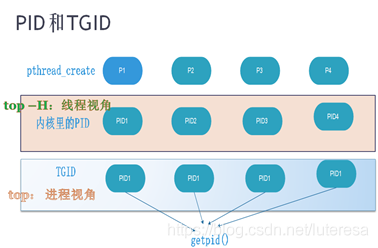
/** * sys_getpid - return the thread group id of the current process * * Note, despite the name, this returns the tgid not the pid. The tgid and * the pid are identical unless CLONE_THREAD was specified on clone() in * which case the tgid is the same in all threads of the same group. * * This is SMP safe as current->tgid does not change. */ SYSCALL_DEFINE0(getpid) { return task_tgid_vnr(current); } ...... staticinlinepid_ttask_tgid_vnr(struct task_struct *tsk) { return pid_vnr(task_tgid(tsk)); } ...... staticinline struct pid *task_tgid(struct task_struct *task) { return task->group_leader->pids[PIDTYPE_PID].pid; }
ENTRY(entry_SYSCALL_64) /* * Interrupts are off on entry. * We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON, * it is too small to ever cause noticeable irq latency. */ SWAPGS_UNSAFE_STACK /* * A hypervisor implementation might want to use a label * after the swapgs, so that it can do the swapgs * for the guest and jump here on syscall. */ GLOBAL(entry_SYSCALL_64_after_swapgs)
/* Construct struct pt_regs on stack */ pushq $__USER_DS /* pt_regs->ss */ pushq PER_CPU_VAR(rsp_scratch)/* pt_regs->sp */// 压至对应线程的内核栈 /* * Re-enable interrupts. * We use 'rsp_scratch' as a scratch space, hence irq-off block above * must execute atomically in the face of possible interrupt-driven * task preemption. We must enable interrupts only after we're done * with using rsp_scratch: */ ENABLE_INTERRUPTS(CLBR_NONE) pushq %r11 /* pt_regs->flags */ pushq $__USER_CS /* pt_regs->cs */ pushq %rcx /* pt_regs->ip */ pushq %rax /* pt_regs->orig_ax */ pushq %rdi /* pt_regs->di */ pushq %rsi /* pt_regs->si */ pushq %rdx /* pt_regs->dx */ pushq %rcx /* pt_regs->cx */ pushq $-ENOSYS /* pt_regs->ax */ pushq %r8 /* pt_regs->r8 */ pushq %r9 /* pt_regs->r9 */ pushq %r10 /* pt_regs->r10 */ pushq %r11 /* pt_regs->r11 */ sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */ ...... RESTORE_C_REGS_EXCEPT_RCX_R11 // 恢复所有的寄存器,除了rcx以及r11 movq RIP(%rsp), %rcx // 单独恢复rcx,因为在调用USERGS_SYSRET64之前,需要将需要返回的用户态地址(syscall下一行指令的地址)保存在rcx中 movq EFLAGS(%rsp), %r11 // 恢复r11,将老的eflags加载入r11 movq RSP(%rsp), %rsp // 恢复旧的用户态rsp /* * 64-bit SYSRET restores rip from rcx, * rflags from r11 (but RF and VM bits are forced to 0), * cs and ss are loaded from MSRs. * Restoration of rflags re-enables interrupts. * * NB: On AMD CPUs with the X86_BUG_SYSRET_SS_ATTRS bug, the ss * descriptor is not reinitialized. This means that we should * avoid SYSRET with SS == NULL, which could happen if we schedule, * exit the kernel, and re-enter using an interrupt vector. (All * interrupt entries on x86_64 set SS to NULL.) We prevent that * from happening by reloading SS in __switch_to. (Actually * detecting the failure in 64-bit userspace is tricky but can be * done.) */ USERGS_SYSRET64
ENTRY(entry_SYSCALL_64) /* * Interrupts are off on entry. * We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON, * it is too small to ever cause noticeable irq latency. */ SWAPGS_UNSAFE_STACK /* * A hypervisor implementation might want to use a label * after the swapgs, so that it can do the swapgs * for the guest and jump here on syscall. */ GLOBAL(entry_SYSCALL_64_after_swapgs)
/* Construct struct pt_regs on stack */ pushq $__USER_DS /* pt_regs->ss */ pushq PER_CPU_VAR(rsp_scratch)/* pt_regs->sp */ /* * Re-enable interrupts. * We use 'rsp_scratch' as a scratch space, hence irq-off block above * must execute atomically in the face of possible interrupt-driven * task preemption. We must enable interrupts only after we're done * with using rsp_scratch: */ ENABLE_INTERRUPTS(CLBR_NONE) pushq %r11 /* pt_regs->flags */ pushq $__USER_CS /* pt_regs->cs */ pushq %rcx /* pt_regs->ip */ pushq %rax /* pt_regs->orig_ax */ pushq %rdi /* pt_regs->di */ pushq %rsi /* pt_regs->si */ pushq %rdx /* pt_regs->dx */ pushq %rcx /* pt_regs->cx */ pushq $-ENOSYS /* pt_regs->ax */ pushq %r8 /* pt_regs->r8 */ pushq %r9 /* pt_regs->r9 */ pushq %r10 /* pt_regs->r10 */ pushq %r11 /* pt_regs->r11 */ sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
testl $_TIF_WORK_SYSCALL_ENTRY, ASM_THREAD_INFO(TI_flags, %rsp, SIZEOF_PTREGS) jnz tracesys entry_SYSCALL_64_fastpath: #if __SYSCALL_MASK == ~0 cmpq $__NR_syscall_max, %rax #else andl $__SYSCALL_MASK, %eax cmpl $__NR_syscall_max, %eax #endif ja 1f/* return -ENOSYS (already in pt_regs->ax) */ movq %r10, %rcx call *sys_call_table(, %rax, 8) movq %rax, RAX(%rsp) 1: /* * Syscall return path ending with SYSRET (fast path). * Has incompletely filled pt_regs. */ LOCKDEP_SYS_EXIT /* * We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON, * it is too small to ever cause noticeable irq latency. */ DISABLE_INTERRUPTS(CLBR_NONE)
/* * We must check ti flags with interrupts (or at least preemption) * off because we must *never* return to userspace without * processing exit work that is enqueued if we're preempted here. * In particular, returning to userspace with any of the one-shot * flags (TIF_NOTIFY_RESUME, TIF_USER_RETURN_NOTIFY, etc) set is * very bad. */ testl $_TIF_ALLWORK_MASK, ASM_THREAD_INFO(TI_flags, %rsp, SIZEOF_PTREGS) jnz int_ret_from_sys_call_irqs_off /* Go to the slow path */
RESTORE_C_REGS_EXCEPT_RCX_R11 movq RIP(%rsp), %rcx movq EFLAGS(%rsp), %r11 movq RSP(%rsp), %rsp /* * 64-bit SYSRET restores rip from rcx, * rflags from r11 (but RF and VM bits are forced to 0), * cs and ss are loaded from MSRs. * Restoration of rflags re-enables interrupts. * * NB: On AMD CPUs with the X86_BUG_SYSRET_SS_ATTRS bug, the ss * descriptor is not reinitialized. This means that we should * avoid SYSRET with SS == NULL, which could happen if we schedule, * exit the kernel, and re-enter using an interrupt vector. (All * interrupt entries on x86_64 set SS to NULL.) We prevent that * from happening by reloading SS in __switch_to. (Actually * detecting the failure in 64-bit userspace is tricky but can be * done.) */ USERGS_SYSRET64